Deploying the model built in Part 1 to a betting scheme to see what kind of money can (hypothetically) be made.
Choosing the Timeframe and Model Usage 🔗
I’ll be using the neural network from part 1 and the years 2021-2024 for testing betting strategies. In order to keep the model from seeing any data from the future, I will only train it on matches from the past. Every 1000 bets made I will retrain the model to include the matches that “just happened”. I’m interested in re-training the model at the start of every tournament (as opposed to an arbitrary number like every 1000 matches), but I will come back to that another time.
The Data 🔗
The betting odds data comes from here. The files were a bit of a hassle to combine because the tournament names and player names aren’t stored the same, so some matches were lost when combining the betting data with the model data. Also the ATP Tour match data was more robust than the betting odds data, so the matches which didn’t overlap were also lost. I’ll be using the best odds given for either the favorite or underdog, as I imagine any good sports bettor would. It’s important to be careful of keeping the odds data separated from the feature data, as a mixture of the two would obviously lead to biased results.
The Betting Strategy 🔗
The Kelly criterion is a method of bet sizing which has been popular for a long time. In essence, you want to bet more on games where you either stand to win a lot or have a high probability of winning, and bet less otherwise. The formula, in which f* is a fraction of your bankroll, is given by:
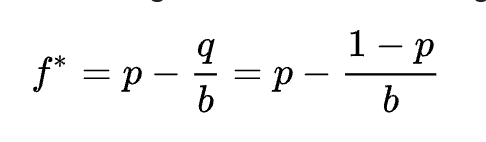
There are two variations of the Kelly criterion that I will be testing. The first is the Half-Kelly, which just divides the formula above by two. Simple enough - smaller bets are more prudent. The other variation comes from a paper by Baker and Mchale. I recommend you check it out, it’s a bit dense for getting into here. But the formula for f* (k*) becomes:
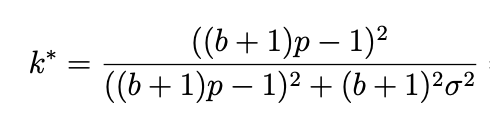
You’ll notice the σ term, wich represents the error variance of the predictions. Different values for this parameter will have to be expiremented with to see which yields the best results.
The last component of the betting strategy is when to make a bet. You don’t have to bet on everything - as the predicted odds near the bookmaker’s odds the bet size will get quite small, but we can also choose just to pass over these bets and be more prudent.
The Data, Revisited 🔗
Remember when I said that combining the data was a bit of a hassle? Well, it’s actually a lot of a hassle. Not only are the names of the tournaments stored differently, but one dataset stores the beginning date of the tournament whereas the other uses the specific match the date was played on. Combined with the fact some players play each other often, or even multiple times at the same tournament (in different years of course), this is more of a headache than I anticipated. These problems are not the end of the world, but they will require some perseverance.